![Mince Pies]() CC-BY-SA 2.0 image by Phil! Gold
CC-BY-SA 2.0 image by Phil! Gold
Since joining Cloudflare I’ve always known that as we grew, incredible things would be possible. It’s been a long held ambition to work in an organisation with the scale to answer a very controversial and difficult question. To do so would require a collection of individuals with a depth of experience, passion, dedication & above all collaborative spirit.
As Cloudflare’s London office has grown in the last 4 years I believe 2017 is the year we reach the tipping point where this is possible. A paradigm-shift in the type of challenges Cloudflare is able to tackle. We could finally sample every commercially available mince pie in existence before the 1st of December. In doing so, we would know conclusively which mince pie we should all be buying over Christmas to share with our friends & families.
What is a mince pie?
For the uninitiated, a Mince Pie is “a sweet pie of British origin, filled with a mixture of dried fruits and spices called mincemeat, that is traditionally served during the Christmas season in the English world.” - Wikipedia for Mince Pie
The original Mince Pie was typically filled with a mixture of minced meat, suet and a variety of fruits and spices like cinnamon, cloves and nutmeg. Today, many mince pies are vegetarian-friendly, containing no meat or suet. They are churned out by both large commercial operations and 200 year-old, family-run bakeries alike to feed hungry Brits at Christmas. Some factories peak at at more than 27pps (pies per second).
![Mince Pie Sketch]()
Review Methodology
Early on we settled on 4 key metrics to score each pie on, on a scale from 1-10. When reviewing anything with a scientific approach, consistency is key. Much like a well made pastry case.
What does and does not constitute a pie?
Very quickly we realised that we needed some hard rules on what counted as a pie. For example, we had some "Frangipane Mince Pies" from Marks & Spencer which caused a lot of controversy– these do not have a top, but instead cover the mince with a baked frangipane.
![]()
Although these rule-breaking pies were not included in our leaderboard, they're definitely worth a try... one reviewer described the filling as “inoffensive” and another left these comments;
"ZERO air gap! How do you solve the problem of an air gap in your pie? Fill it with some delicious tasty frangipane, that's how. The crunchy almonds on the top really cut through the softness with some texture, too. Most excellent."
Tom Arnfeld, Systems Engineer
Pastry / Filling Ratio
The ratio is really key to a good mince pie, but it is also possible for other aspects of the pie to be bad while the ratio itself is excellent. To be clear (there was confusion and debate internally) a score of 5/10 ratio would mean the ratio was average in quality. It does not directly measure the ratio itself. A 10/10 would have the perfect ratio of pastry to mince. Air gap was also a consideration, and the detailed comments each reviewer made on each pie often explain this.
Pastry
The right pastry needs to be not too thick, crispy but still have chew and be moist but not soggy. It should hold the filling without it spilling out.
Filling
The filling itself is probably the thing most pies were scored harshly on. A good filling has a variety of fruits and textures and possibly even some other flavours such as brandy.
Overall
We left it to each reviewer to add an overall score judging the entire pie.
Results
30 types of mince pie, 68 reviewers, 18 hungry Cloudflare staff.
Top 5 Pies
After collecting all of the reviews together, here’s our top 5 pies.
£0.75p per pie
![]()
Look, I'm going to get straight to it: if you are a mince pie traditionalist, these are not the mince pies for you. HOWEVER, for me they were a revelation. They push boundaries, break all the rules but somehow retain the essence of a great mince pie.
Pastry: TWO DIFFERENT TYPES for the base and the topping. Some people have an issue with the pastry 'rubble' on top. I found it DELIGHTFUL. 9/10
Filling: Not only was there excellent standard mincemeat, but also there was a thin layer of lemon jelly in there as well. SPLENDID. Strong nutmeg and clove themes throughout.
Extra marks for the surreal box art. ("Ceci n'est pas une pie")
Sam Howson, Support Engineer
£1.35p per pie
Pastry / Filling Ratio: Absolutely no visible air gap. TFL could learn from this. Actually fulfilling the promise of deep filled for the first time ever. 10/10
Pastry: Really great. Well constructed, cooked & even all the way around. We've said this a lot but probably "needs more butter" 8/10
Filling: Ironically the reason I like this is also the reason why it's not getting a 10. The citrus - it's so good to have some citrus in there - sorely lacking in lots of other fillings. But it's just too much - it's really the only discernible flavour. Some booze wouldn't go amiss here. 8/10
Overall: This competition might be Dunn Dunn Dunn. Spectacular. 8.5
Simon Moore, Lead Customer Support Engineer
3. Fortnum & Mason
£1.83p per pie
These were by far the most controversial, from our reviewers' point of view.
Pastry / Filling Ratio: About right... a well filled pie with little air gap and a pastry that wasn't so thick that it would diminish the filling. 9/10
Pastry: The weakest part, butter and soft, lovely all over... except that the base was also like this and needed to be a bit crisper and less soft. 7/10
Filling: Subtle flavours, good spices, a hint of Christmas warmth. Could be improved with a little more aftertaste like the K&C ones had, but this is a good filling and with lots of filling, very tasty. 8/10
Overall: A pretty good pie, one of the best yet but the pastry not being crisp and solid underneath makes it fall apart in your hands a little. 8/10
David Kitchen, Engineering Manager
For contrast, one anomalous reviewer wrote;
Pastry / Filling Ratio: EXCELLENT. The pie is deep, and with little air gap. Other reviews mention an air gap however, so QC is clearly not a priority in spite of its cost. 9/10
Pastry: Just fine. Kind of dry, not very buttery. Sugar was nice on top, but really nothing to write home about. Structurally this pie was terrible as the lid lifted clean off when I tried to get it out of its tin. 4/10
Filling: The worst part of this pie, by a massive margin. The mince was almost a pureé, with no discernable fruit textures. Very lightly spiced, again with no flavour components of it being distinguishable. Lack of texture here made it feel like a mince pie for the elderly or small children as after the pastry had disintegrated, there was nothing to chew. 3/10
Overall: Decadently priced farce of a pie filled with a disappointment flavoured mincemeat. Might as well have been packaged in a Londis box. As my girlfriend said "That sounds like it needs covering in cream and then putting in the bin". I wholeheartedly agree. 3/10
Bhavin Tailor, Support Engineer
4. Marks & Spencer Standard Mince Pies (red box)
(price unknown)
Pastry / Filling Ratio: Filled to the brim. Excellent! 9/10
Pastry: Buttery, right thickness, just lovely. Although a bit too much on the sweet side. 7/10
Filling: Great! Nice flavours, still some texture, nothing overwhelms the other flavours. Just wonderful. 8/10
Overall: Great pastry, could eat it all day. 8/10
Tom Strickx, Network Automation Engineer
£0.33p per pie
Pastry / Filling Ratio: Massive air gap. Probably has more air than mince, which is very disappointing. 5/10
Pastry: Buttery, but a bit too thick. Feels a bit heavy. 7/10
Filling: Very noticeable brandy smell, luckily not as present in the taste. Subtle brandy flavour, but doesn't overwhelm the actual mince. A+ 9/10
Overall: Great flavour, love the touch of brandy, unfortunately a bit let down by the filling ratio, and the heaviness of the crust. 7/10
Tom Strickx, Network Automation Engineer
Other Entrants
While on our quest to try every pie on the market, we encountered some great ones that are worth a mention. Of aldi mince pies we've tried a single Marks & Spencer pie asda best taste of all, but one had the lidlest per pie cost.
Greggs
£0.25p per pie
Pastry / Filling Ratio: There's no easy way of saying this, there's more pastry here than there are Greggs branches in Coventry. The only way I would score this lower was if there was no mince at all and I was just eating a solid puck of pastry. 1/10
Pastry: Overcooked, brittle and really just miserable. I'm giving it a point only because it exists. 1/10
Filling: Sweet & Bland. 1/10
Overall: Horrible. 1/10
Simon Moore, Lead Customer Support Engineer
Bigger than the standard supermarket ones, which is definitely nice.
Pastry / Filling Ratio: I think kids these day call it "dat gap". Unfortunately in this case, it's not a good thing.
Pastry: Buttery, crumbly, good thickness, bit bland. 6/10
Filling: Bit bland as well, no specific highlights or notes of flavour. 6/10
Overall: Pretty bland, but not too shabby.
Tom Strickx, Network Automation Engineer
Costco
£0.44p per pie
![]()
Pastry/Filling Ratio: 9/10 To solve the problem of the 'air gap', Costco decided to top the mince pie with sponge cake. This technically makes the pastry/filling ratio near-perfect since the tiny amount of pastry on the outside matches the tiny amount of filling. Well played, Costco.
Pastry: 3/10 The pastry itself is acceptable but minimal - the majority of the cake is sponge. Yes, I said cake - this is no pie.
Filling: 1/10 They decided to fill it one currant high. And not even like a currant standing proud like the California Raisins, this is a teensy portion. I'm pretty sure the icing on top is thicker than the filling.
Overall: 2/10 This is not a mince pie, it's clearly a sugar cake that has some regulation-mandated minimum amount of mincemeat content to call it a mince pie. Making the 'pies' huge doesn't compensate for anything. Poor showing, Costco.
Chris Branch, Systems Engineer
Mr Kipling
£0.25p per pie (from Tesco)
Pastry / Filling Ratio: 5/10
Pastry: More salty than buttery. 4/10
Filling: Drabness cloaked in excessive sweetness. 4/10
Mr Kipling purports his products to be "exceedingly good" in his television advertisements, but this pie did not lend support to that claim.
David Wragg, Systems Engineer
Aldi (Cognac Steeped)
£0.38p per pie
Pastry / Filling Ratio: This pie has more air than Michael Jordan 4/10
Pastry: Good but far too thick on the lid. 6/10
Filling: I can detect the booze but it's just not really adding anything. There's nothing of distinction here. 5/10
Overall: 4/10 The ratio and the lid spoil what would otherwise be a serviceable mince pie.
Simon Moore, Lead Customer Support Engineer
Jimmy’s Home-made Pies
With so many mince pies moving through the office on a daily basis, one of our resident staff bakers decided to bake some of his own to add into the mix. Jimmy Crutchfield (Systems Reliability Engineer) brought in 12 lovingly made pies for us all to try...
![Jimmy Alpha]()
Pastry / Filling Ratio: Nice and deep, but a little too moist. Surprising given apparently the mincemeat was shop bought – you'd think it would have the right consistency.
Pastry: The pastry was pretty well cooked, and not too dry. I think it could do with a bit more butter though. 8/10
Filling: The added apple bits introduced some delightful new texture. 6/10
Overall: Little in the way of decoration on the top, though bonus points for the lovingly home-made look. Pretty excited about the next version. 9/10
Tom Arnfeld, Systems Engineer
A couple of weeks later, Jimmy had his hand at making a second batch, too!
![]()
Pastry / Filling Ratio: Small air gap. 8/10
Pastry: Buttery & crumbly, very good. 9/10
Filling: Just a little too tart. 8/10
Overall: I'd be happy if i'd paid for a box of them. 9/10
Michael Daly, Systems Reliability Engineering Manager
Falling by the wayside
There are too many pies and reviews to mention in full detail, but here’s a full list of the other pies we haven’t mentioned, sorted by their rating.
- Sainsbury’s Bakery (fresh)
- Carluccio’s
- Coco di Mama Mini Mince Pies
- Riverford Farm Shop Classic
- Tesco Standard
- Marks & Spencer Lattice-top
- Marks & Spencer All Butter
- Tesco Finest (with Cognac)
- Aldi Sloe Gin Mince Tarts
- Waitrose All Butter
- Gail’s
- LIDL Favorina
- Co-op Irresistible
- Sainsbury’s Deep Filled
- LIDL Brandy Butter
- Aldi Almond Mince Tarts
With so many reviews from so many staff, we’d like to thank everyone that took part in our quest! Alex Palaistras, Bhavin Tailor, Chris Branch, David Kitchen, David Wragg, Etienne Labaume, John Graham-Cumming, Jimmy Crutchfield, Lorenz Bauer, Matthew Bullock, Michael Daly, Sam Howson, Scott Pearson, Simon Moore, Sophie Bush, Tim Ruffles, Tom Arnfeld, Tom Strickx.
If you want to join a passionate, dedicated, talented and mince pie-filled team - we’re hiring!


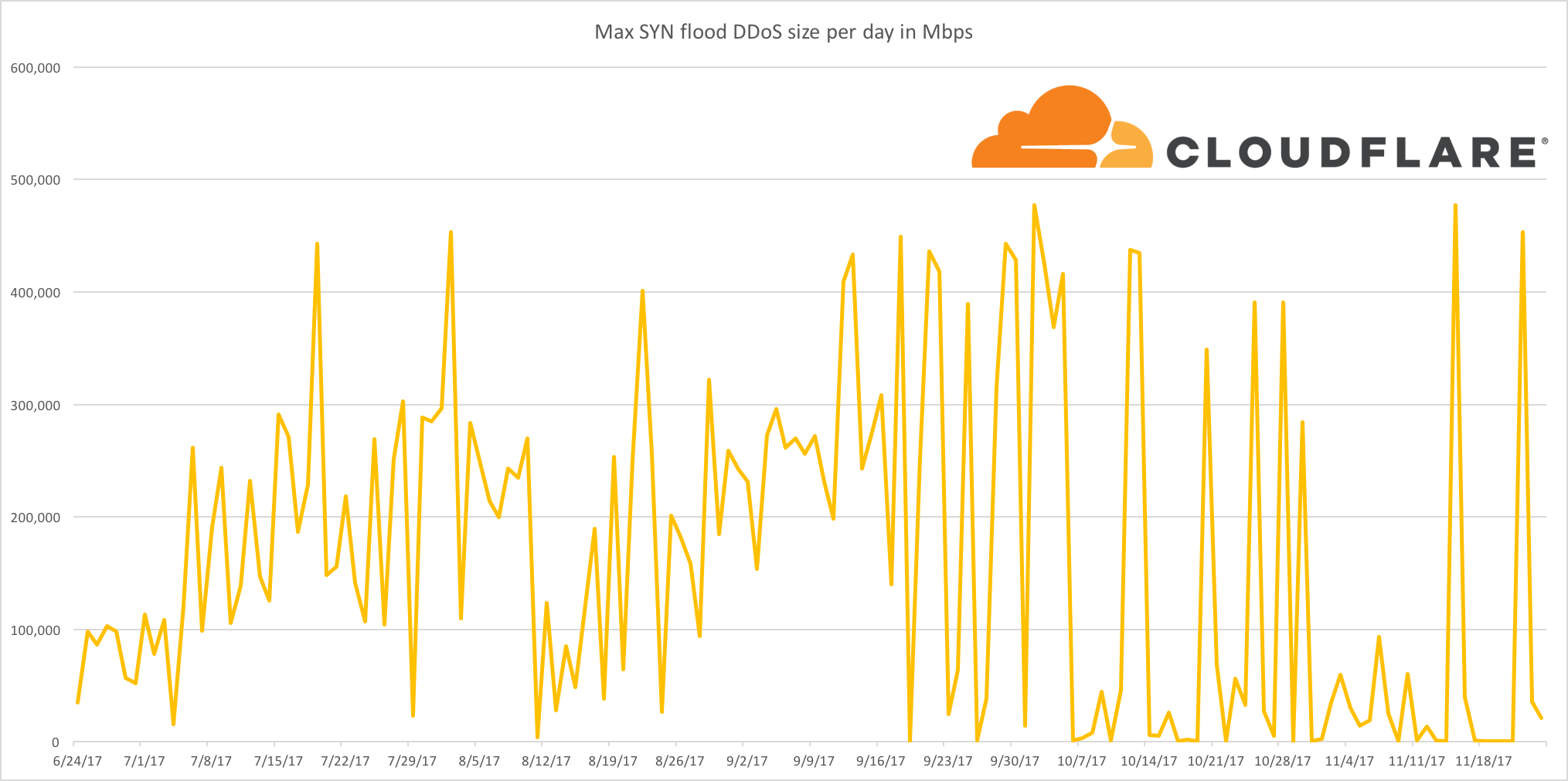
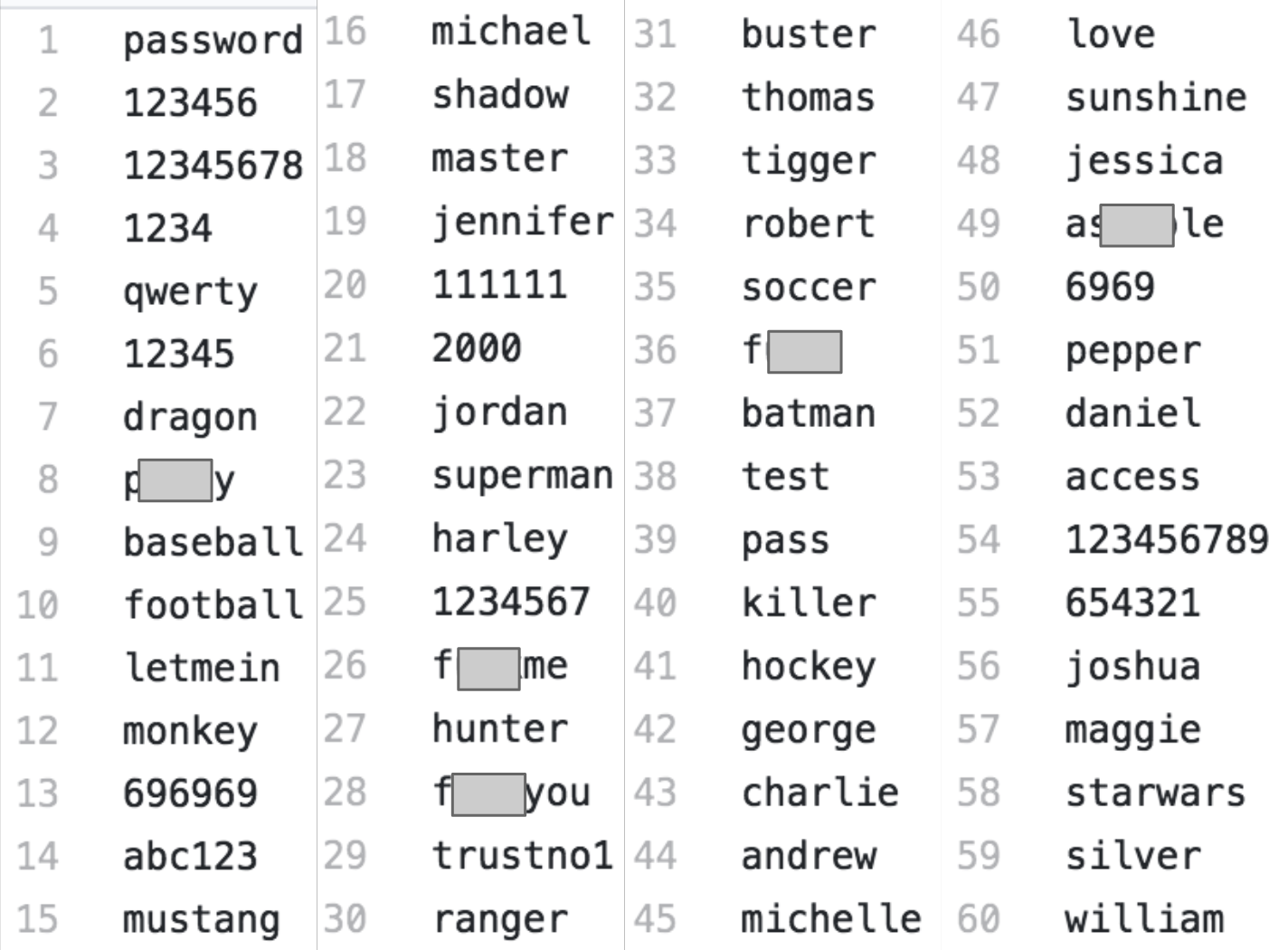
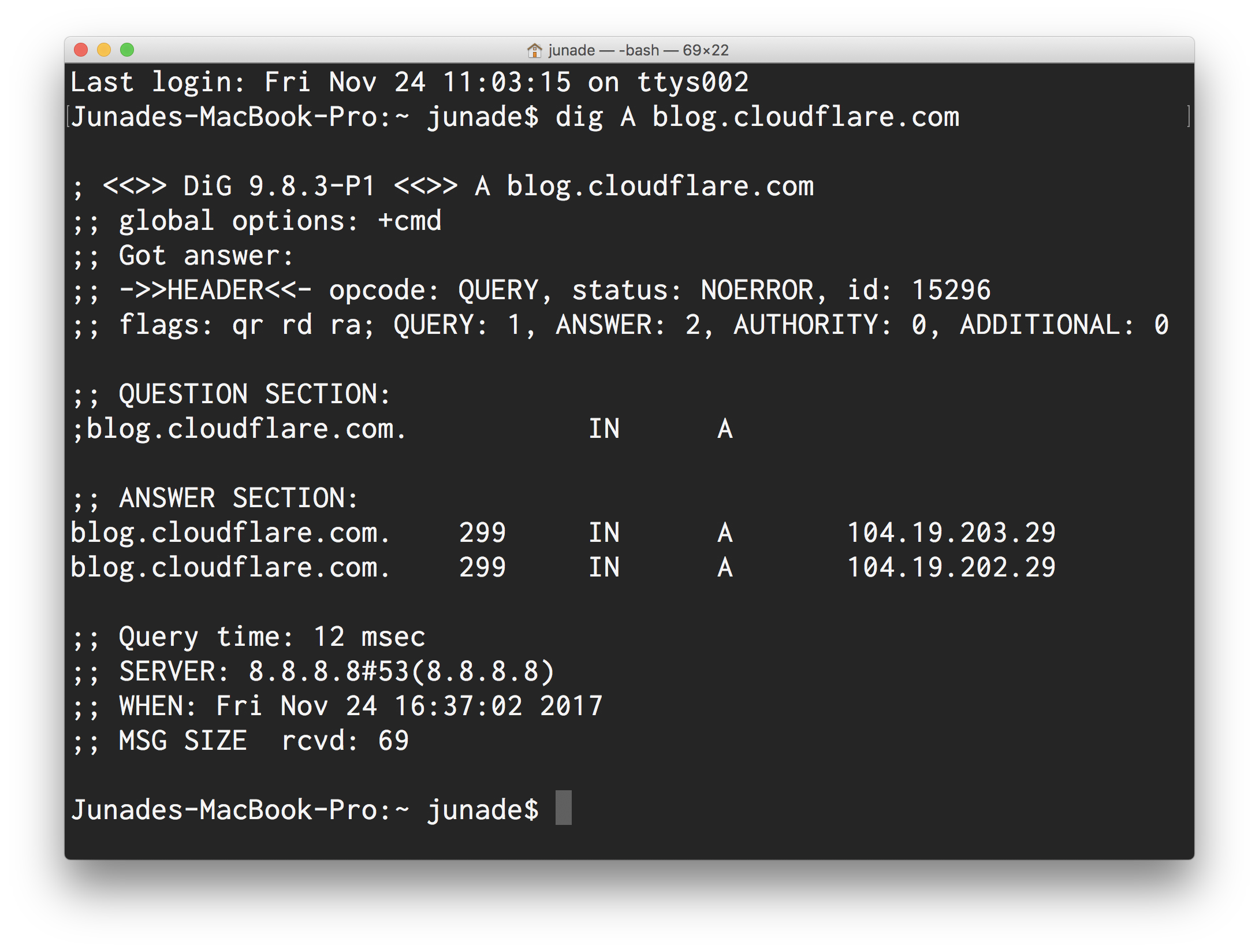
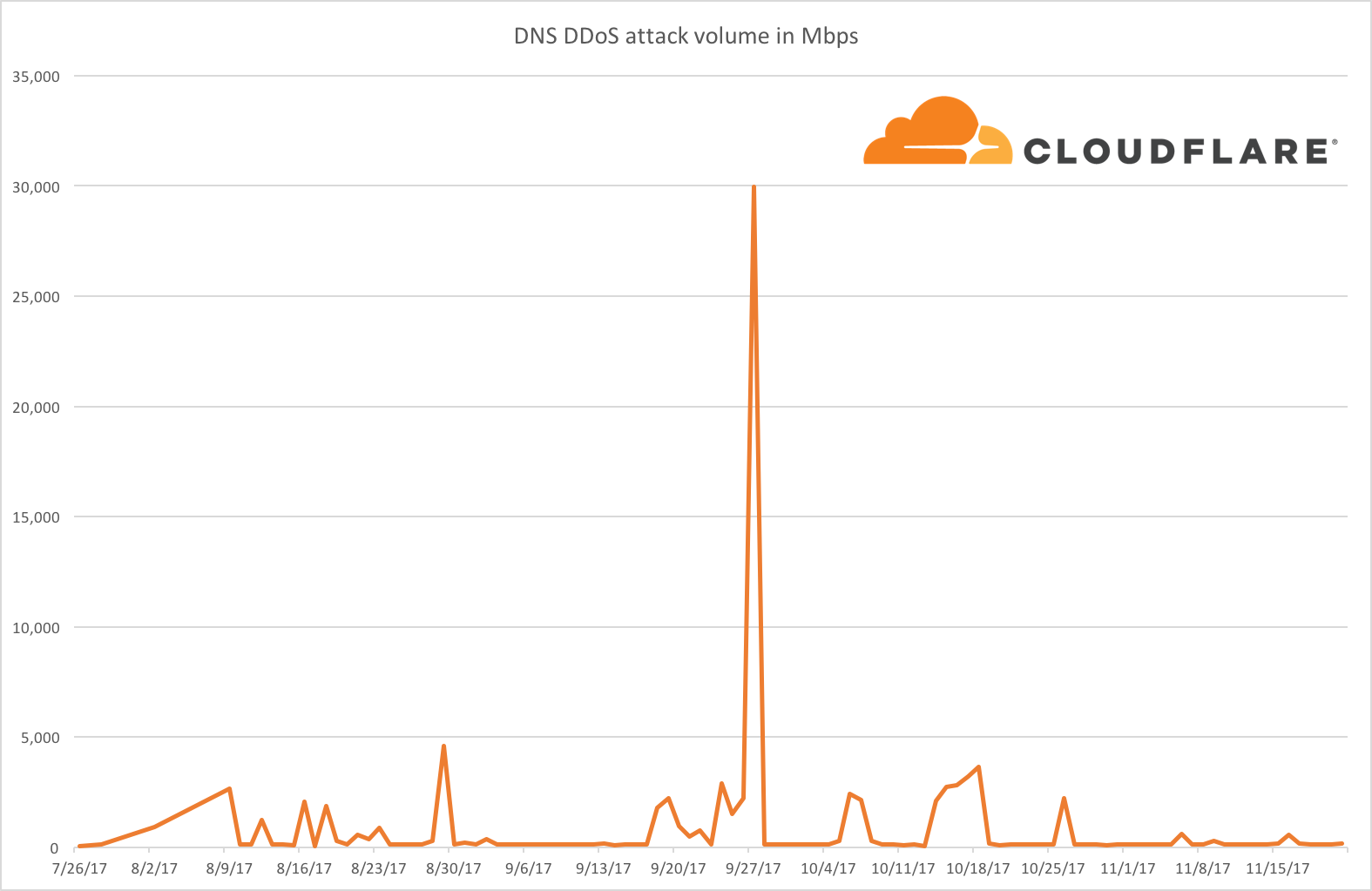











 Jurassic Park. 1993, Stephen Spielberg [Film] Universal Pictures.
Jurassic Park. 1993, Stephen Spielberg [Film] Universal Pictures.
















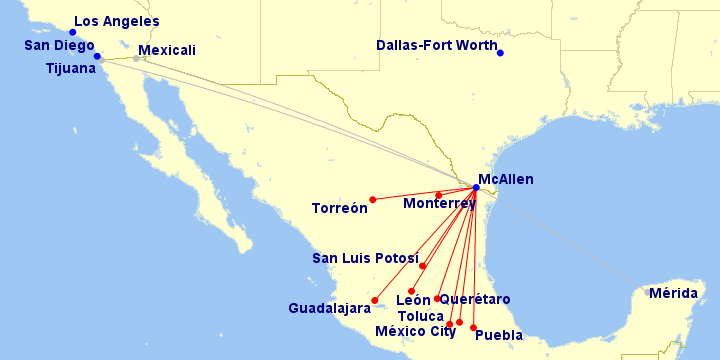 Image courtesy of gcmap service
Image courtesy of gcmap service Image, with permission, from
Image, with permission, from 







 Example Waterfall view from WebSiteOptimization.com
Example Waterfall view from WebSiteOptimization.com