![Why TLS 1.3 isn't in browsers yet]()
![Why TLS 1.3 isn't in browsers yet]()
Upgrading a security protocol in an ecosystem as complex as the Internet is difficult. You need to update clients and servers and make sure everything in between continues to work correctly. The Internet is in the middle of such an upgrade right now. Transport Layer Security (TLS), the protocol that keeps web browsing confidential (and many people persist in calling SSL), is getting its first major overhaul with the introduction of TLS 1.3. Last year, Cloudflare was the first major provider to support TLS 1.3 by default on the server side. We expected the client side would follow suit and be enabled in all major browsers soon thereafter. It has been over a year since Cloudflare’s TLS 1.3 launch and still, none of the major browsers have enabled TLS 1.3 by default.
The reductive answer to why TLS 1.3 hasn’t been deployed yet is middleboxes: network appliances designed to monitor and sometimes intercept HTTPS traffic inside corporate environments and mobile networks. Some of these middleboxes implemented TLS 1.2 incorrectly and now that’s blocking browsers from releasing TLS 1.3. However, simply blaming network appliance vendors would be disingenuous. The deeper truth of the story is that TLS 1.3, as it was originally designed, was incompatible with the way the Internet has evolved over time. How and why this happened is the multifaceted question I will be exploring in this blog post.
To help support this discussion with data, we built a tool to help check if your network is compatible with TLS 1.3:
https://tls13.mitm.watch/
How version negotiation used to work in TLS
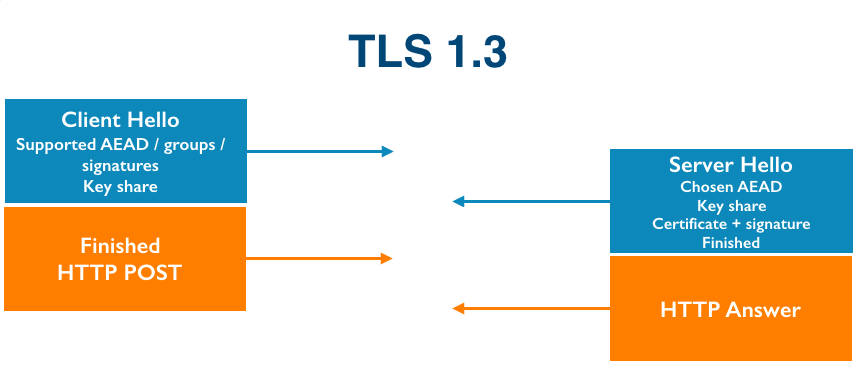
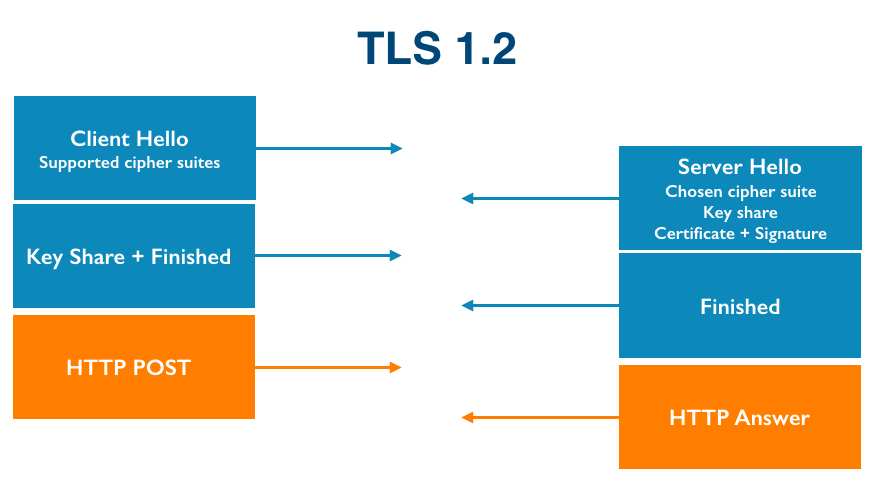
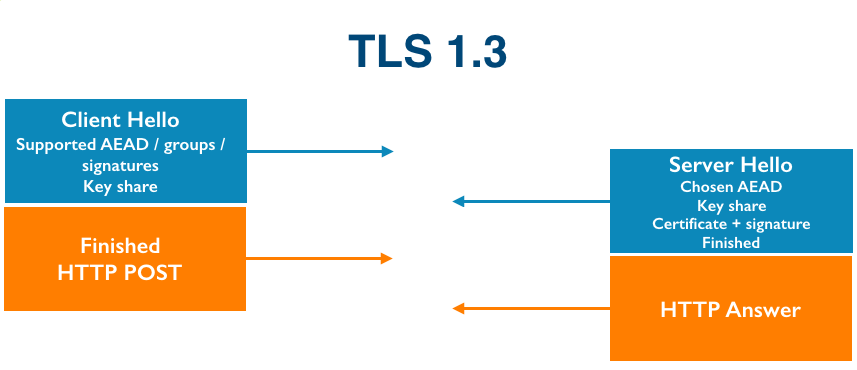
The Transport Layer Security protocol, TLS, is the workhorse that enables secure web browsing with HTTPS. The TLS protocol was adapted from an earlier protocol, Secure Sockets Layer (SSL), in the late 1990s. TLS currently has three versions: 1.0, 1.1 and 1.2. The protocol is very flexible and can evolve over time in different ways. Minor changes can be incorporated as “extensions” (such as OCSP and Certificate Transparency) while larger and more fundamental changes often require a new version. TLS 1.3 is by far the largest change to the protocol in its history, completely revamping the cryptography and introducing features like 0-RTT.
Not every client and server support the same version of TLS—that would make it impossible to upgrade the protocol—so most support multiple versions simultaneously. In order to agree on a common version for a connection, clients and servers negotiate. TLS version negotiation is very simple. The client tells the server the newest version of the protocol that it supports and the server replies back with the newest version of the protocol that they both support.
Versions in TLS are represented as two-byte values. Since TLS was adapted from SSLv3, the literal version numbers used in the protocol were just increments of the minor version:
SSLv3 is 3.0
TLS 1.0 is 3.1
TLS 1.1 is 3.2
TLS 1.2 is 3.3, etc.
When connecting to a server with TLS, the client sends its highest supported version at the beginning of the connection:
(3, 3) → server
A server that understands the same version can reply back with a message starting with the same version bytes.
(3, 3) → server
client ← (3, 3)
Or, if the server only knows an older version of the protocol, it can reply with an older version. For example, if the server only speaks TLS 1.0, it can reply with:
(3, 3) → server
client ← (3, 1)
If the client supports the version returned by the server then they continue using that version of TLS and establish a secure connection. If the client and server don’t share a common version, the connection fails.
This negotiation was designed to be future-compatible. If a client sends higher version than the server supports, the server should still be able to reply with whatever version the server supports. For example, if a client sends (3, 8) to a modern-day TLS 1.2-capable server, it should just reply back with (3,3) and the handshake will continue as TLS 1.2.
Pretty simple, right? As it turns out, some servers didn’t implement this correctly and this led to a chain of events that exposed web users to a serious security vulnerability.
POODLE and the downgrade dance
![Why TLS 1.3 isn't in browsers yet]()
CC0 Creative Commons
The last major upgrade to TLS was the introduction of TLS 1.2. During the roll-out of TLS 1.2 in browsers, it was found that some TLS 1.0 servers did not implement version negotiation correctly. When a client connected with a TLS connection advertising support for TLS 1.2, the faulty servers would disconnect instead of negotiating a version of TLS that they understood (like TLS 1.0).
Browsers had three options to deal with this situation
- enable TLS 1.2 and a percentage of websites would stop working
- delay the deployment of TLS 1.2 until these servers are fixed
- retry with an older version of TLS if the connection fails
One expectation that people have about their browsers is that when they are updated, websites keep working. The number of misbehaving servers was far too numerous to just break with an update, eliminating option 1). By this point, TLS 1.2 had been around for a year, and still, servers were still broken waiting longer wasn’t going to solve the situation, eliminating option 2). This left option 3) as the only viable choice.
To both enable TLS 1.2 and keep their users happy, most browsers implemented what’s called an “insecure downgrade”. When faced with a connection failure when connecting to a site, they would try again with TLS 1.1, then with TLS 1.0, then if that failed, SSLv3. This downgrade logic “fixed” these broken servers... at the cost of a slow connection establishment. 🤦
However, insecure downgrades are called insecure for a reason. Client downgrades are triggered by a specific type of network failure, one that can be easily spoofed. From the client’s perspective, there’s no way to tell if this failure was caused by a faulty server or by an attacker who happens to be on the path of the connection network. This means that network attackers can inject fake network failures and trick a client into connecting to a server with SSLv3, even if both support a newer protocol. At this point, there were no severe publicly-known vulnerabilities in SSLv3, so this didn’t seem like a big problem. Then POODLE happened.
In October 2014, Bodo Möller published POODLE, a serious vulnerability in the SSLv3 protocol that allows an in-network attacker to reveal encrypted information with minimal effort. Because TLS 1.0 was so widely deployed on both clients and servers, very few connections on the web used SSLv3, which should have kept them safe. However, the insecure downgrade feature made it possible for attackers to downgrade any connection to SSLv3 if both parties supported it (which most of them did). The availability of this “downgrade dance” vector turned the risk posed by POODLE from a curiosity into a serious issue affecting most of the web.
Fixing POODLE and removing insecure downgrade
The fixes for POODLE were:
- disable SSLv3 on the client or the server
- enable a new TLS feature called SCSV.
SCSV was conveniently proposed by Bodo Möller and Adam Langley a few months before POODLE. Simply put, with SCSV the client adds an indicator, called a downgrade canary, into its client hello message if it is retrying due to a network error. If the server supports a newer version than the one advertised in the client hello and sees this canary, it can assume a downgrade attack is happening and close the connection. This is a nice feature, but it is optional and requires both clients and servers to update, leaving many web users exposed.
Browsers immediately removed support for SSLv3, with very little impact other than breaking some SSLv3-only websites. Users with older browsers had to depend on web servers disabling SSLv3. Cloudflare did this immediately for its customers, and so did most sites, but even in late 2017 over 10% of sites measured by SSL Pulse still support SSLv3.
Turning off SSLv3 was a feasible solution to POODLE because SSLv3 was not critical to the Internet. This raises the question: what happens if there’s a serious vulnerability in TLS 1.0? TLS 1.0 is still very widely used and depended on, turning it off in the browser would lock out around 10% of users. Also, despite SCSV being a nice solution to insecure downgrades, many servers don’t support it. The only option to ensure the safety of users against a future issue in TLS 1.0 is to disable insecure fallback.
After several years of bad performance due to the client having to reconnect multiple times, the majority of the websites that did not implement version negotiation correctly fixed their servers. This made it possible for some browsers to remove this insecure fallback:
Firefox in 2015, and Chrome in 2016. Because of this, Chrome and Firefox users are now in a safer position in the event of a new TLS 1.0 vulnerability.
Introducing a new version (again)
Designing a protocol for future compatibility is hard, it’s easy to make mistakes if there isn’t a feedback mechanism. This is the case of TLS version negotiation: nothing breaks if you implement it wrong, just hypothetical future versions. There is no signal to developers that an implementation is flawed, and so mistakes can happen without being noticed. That is, until a new version of the protocol is deployed and your implementation fails, but by then the code is deployed and it could take years for everyone to upgrade. The fact that some server implementations failed to handle a “future” version of TLS correctly should have been expected.
TLS version negotiation, though simple to explain, is actually an example of a protocol design antipattern. It demonstrates a phenomenon in protocol design called ossification. If a protocol is designed with a flexible structure, but that flexibility is never used in practice, some implementation is going to assume it is constant. Adam Langley compares the phenomenon to rust. If you rarely open a door, its hinge is more likely to rust shut. Protocol negotiation in TLS is such a hinge.
Around the time of TLS 1.2’s deployment, the discussions around designing an ambitious new version of TLS were beginning. It was going to be called TLS 1.3, and the version number was naturally chosen as 3.4 (or (3, 4)). By mid-2016, the TLS 1.3 draft had been through 15 iterations, and the version number and negotiation were basically set. At this point, browsers had removed the insecure fallback. It was assumed that servers that weren’t able to do TLS version negotiation correctly had already learned the lessons of POODLE and finally implemented version negotiation correctly. This turned out to not be the case. Again.
When presented with a client hello with version 3.4, a large percentage of TLS 1.2-capable servers would disconnect instead of replying with 3.3. Internet scans by Hanno Böck, David Benjamin, SSL Labs, and others confirmed that the failure rate for TLS 1.3 was very high, over 3% in many measurements. This was the exact same situation faced during the upgrade to TLS 1.2. History was repeating itself.
This unexpected setback caused a crisis of sorts for the people involved in the protocol’s design. Browsers did not want to re-enable the insecure downgrade and fight the uphill battle of oiling the protocol negotiation joint again for the next half-decade. But without a downgrade, using TLS 1.3 as written would break 3% of the Internet for their users. What could be done?
The controversial choice was to accept a proposal from David Benjamin to make the first TLS 1.3 message (the client hello) look like it TLS 1.2. The version number from the client was changed back to (3, 3) and a new “version” extension was introduced with the list of supported versions inside. The server would return a server hello starting with (3, 4) if TLS 1.3 was supported and (3, 3) or earlier otherwise. Draft 16 of TLS 1.3 contained this new and “improved” protocol negotiation logic.
And this worked. Servers for the most part were tolerant to this change and easily fell back to TLS 1.2, ignoring the new extension. But this was not the end of the story. Ossification is a fickle phenomenon. It not only affects clients and servers, but it also affects everything on the network that interacts with a protocol.
The real world is full of middleboxes
![Why TLS 1.3 isn't in browsers yet]()
CC BY-SA 3.0
Readers of our blog may remember a post from earlier this year on HTTPS interception. In it, we discussed a study that measured how many “secure” HTTPS connections were actually intercepted and decrypted by inspection software or hardware somewhere in between the browser and the web server. There are also passive inspection middleboxes that parse TLS and either block or divert the connections based on visible data, such as ISPs that use hostname information (SNI) from TLS connections to block “banned” websites.
In order to inspect traffic, these network appliances need to implement some or all of TLS. Every new device that supports TLS introduces a TLS implementation that makes assumption about how the protocol should act. The more implementations there are, the more likely it is that ossification occurs.
In February of 2017, both Chrome and Firefox started enabling TLS 1.3 for a percentage of their customers. The results were unexpectedly horrible. A much higher percentage of TLS 1.3 connections were failing than expected. For some users, no matter what the website, TLS 1.2 worked but TLS 1.3 did not.
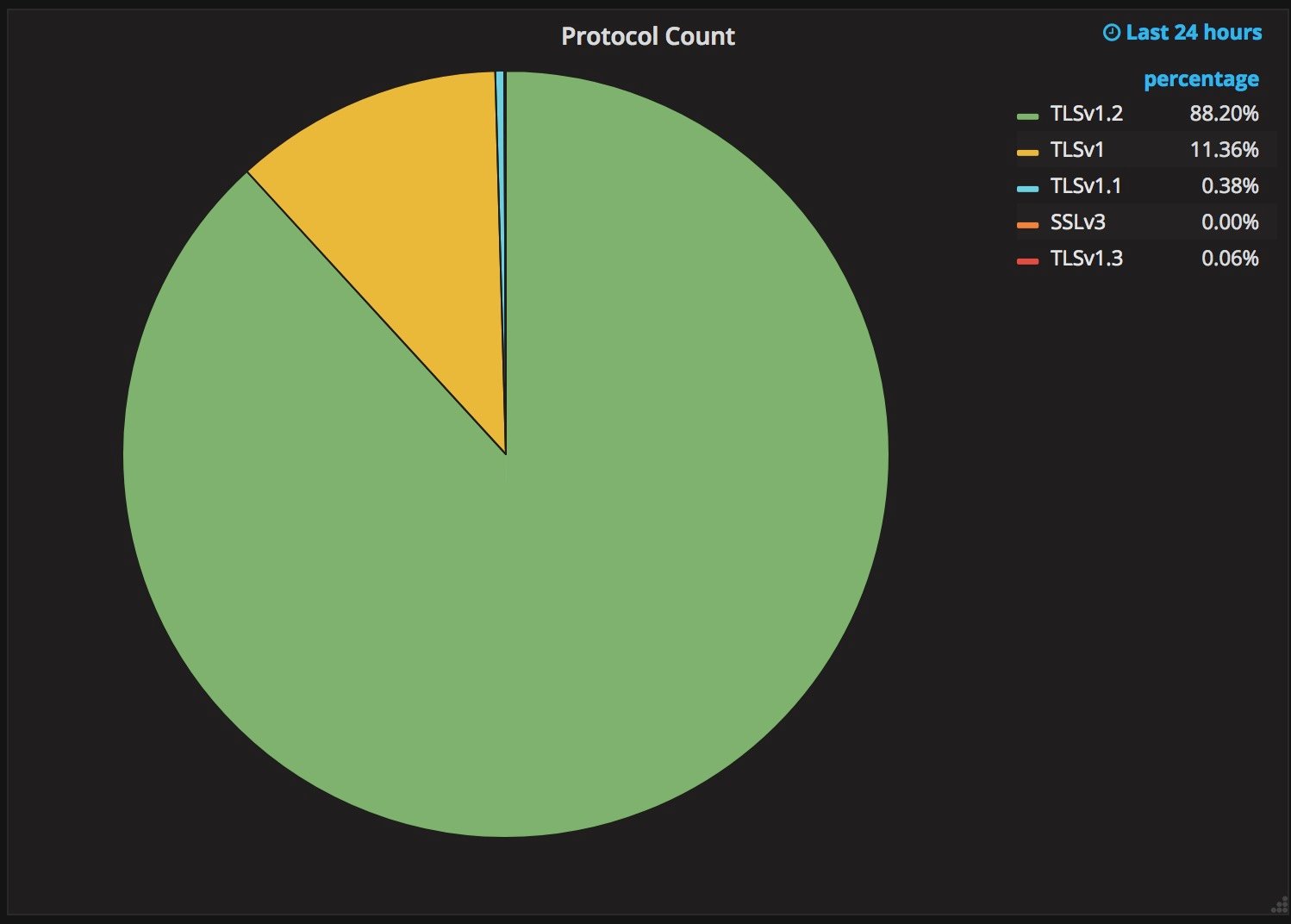
Success rates for TLS 1.3 Draft 18
Firefox & Cloudflare
97.8% for TLS 1.2
96.1% for TLS 1.3
Chrome & Gmail
98.3% for TLS 1.2
92.3% for TLS 1.3
After some investigation, it was found that some widely deployed middleboxes, both of the intercepting and passive variety, were causing connections to fail.
![Why TLS 1.3 isn't in browsers yet]()
Because TLS has generally looked the same throughout its history, some network appliances made assumptions about how the protocol would evolve over time. When faced with a new version that violated these assumptions, these appliances fail in various ways.
Some features of TLS that were changed in TLS 1.3 were merely cosmetic. Things like the ChangeCipherSpec, session_id, and compression fields that were part of the protocol since SSLv3 were removed. These fields turned out to be considered essential features of TLS to some of these middleboxes, and removing them caused connection failures to skyrocket.
If a protocol is in use for a long enough time with a similar enough format, people building tools around that protocol will make assumptions around that format being constant. This is often not an intentional choice by developers, but an unintended consequence of how a protocol is used in practice. Developers of network devices may not understand every protocol used on the internet, so they often test against what they see on the network. If a part of a protocol that is supposed to be flexible never changes in practice, someone will assume it is a constant. This is more likely the more implementations are created.
It would be disingenuous to put all of the blame for this on the specific implementers of these middleboxes. Yes, they created faulty implementations of TLS, but another way to think about it is that the original design of TLS lent itself to this type of failure. Implementers implement to the reality of the protocol, not the intention of the protocol’s designer or the text of the specification. In complex ecosystems with multiple implementers, unused joints rust shut.
Removing features that have been part of a protocol for 20 years and expecting it to simply “work” was wishful thinking.
Making TLS 1.3 work
At the IETF meeting in Singapore last month, a new change was proposed to TLS 1.3 to help resolve this issue. These changes were based on an idea from Kyle Nekritz of Facebook: make TLS 1.3 look like TLS 1.2 to middleboxes. This change re-introduces many of the parts of the protocol that were removed (session_id, ChangeCipherSpec, an empty compression field), and introduces some other changes that make TLS 1.3 look like TLS 1.2 in all the ways that matter to the broken middleboxes.
Several iterations of these changes were developed by BoringSSL and tested in Chrome over a series of months. Facebook also performed some similar experiments and the two teams converged on the same set of changes.
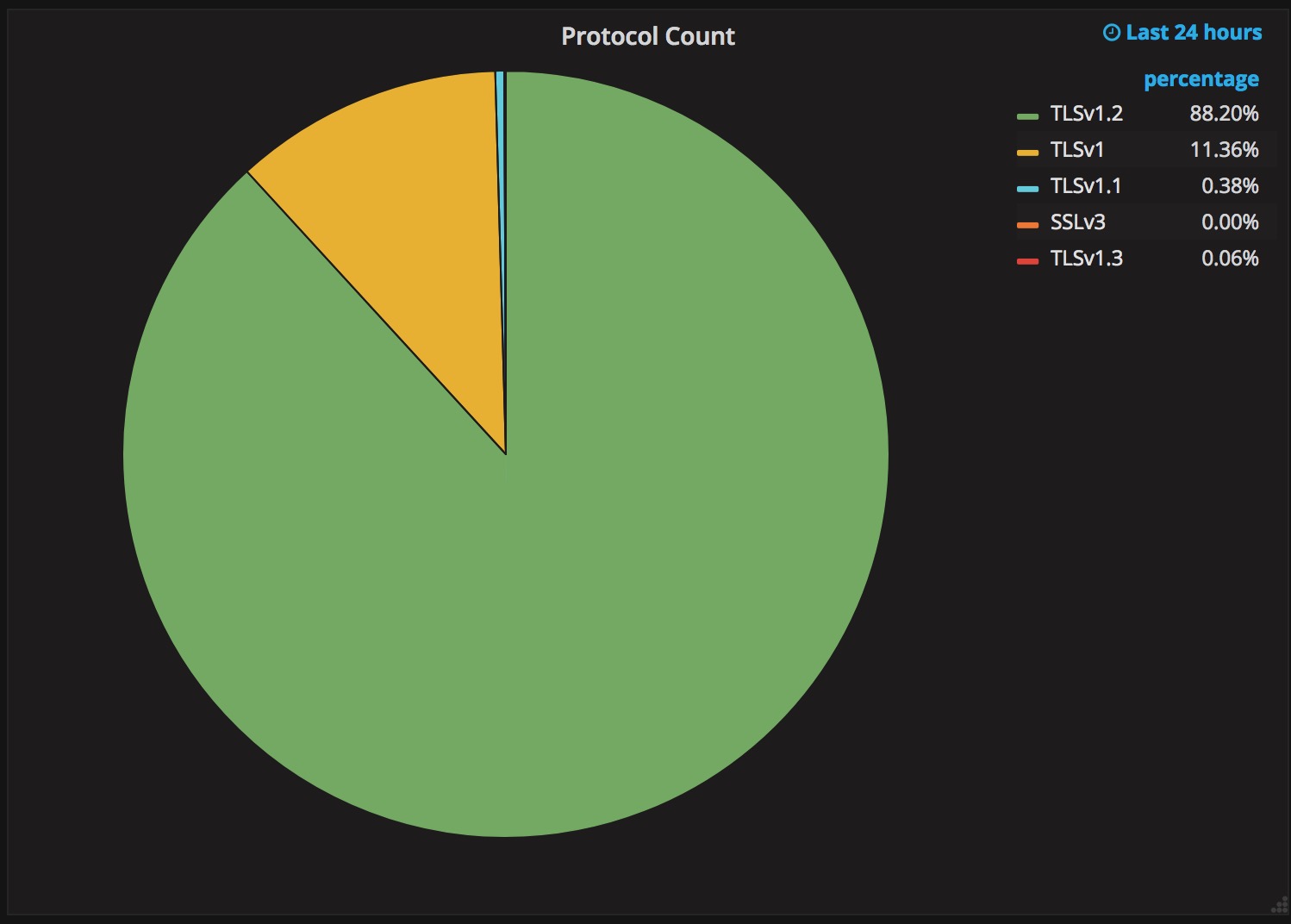
Chrome Experiment Success Rates
TLS 1.2 - 98.6%
Experimental changes (PR 1091 on Github) - 98.8%
Firefox Experiment Success Rates
TLS 1.2 - 98.42%
Experimental changes (PR 1091 on Github) - 98.37%
These experiments showed that is was possible to modify TLS 1.3 to be compatible with middleboxes. They also demonstrated the ossification phenomenon. As we described in a previous section, the only thing that could have rusted shut in the client hello, the version negotiation, rusted shut. This resulted in Draft 16, which moved the version negotiation to an extension. As an intermediary between the client and the server, middleboxes also care about the server hello message. This message had many more hinges that were thought to be flexible but turned out weren’t. Almost all of these had rusted shut. The new “middlebox-friendly” changes took this reality into account. These experimental changes were incorporated into the specification in TLS 1.3 Draft 22.
Making sure this doesn’t happen again
The original protocol negotiation mechanism is unrecoverably burnt. That means it likely can’t be used in a future version of TLS without significant breakage. However, many of the other protocol negotiation features are still flexible, such as ciphersuites selection and extensions. It would be great to keep it this way.
Last year, Adam Langley wrote a great blog post about cryptographic protocol design (https://www.imperialviolet.org/2016/05/16/agility.html) that covers similar ground as this blog post. In his post, he proposes the adage “have one joint and keep it well oiled.” This is great advice for protocol designers. Ossification is real, as we have seen in TLS 1.3.
Along these lines, David Benjamin proposed a way to keep the most important joints in TLS oiled. His GREASE proposal for TLS is designed to throw in random values where a protocol should be tolerant of new values. If popular implementations intersperse unknown ciphers, extensions and versions in real-world deployments, then implementers will be forced to handle them correctly. GREASE is like WD-40 for the Internet.
One thing to note is that GREASE is intended to prevent servers from ossifying, not middleboxes, so there is still potential for more types of greasing to happen in TLS.
Even with GREASE, some servers were only found to be intolerant to TLS 1.3 as late as December 2017. GREASE only identifies servers that are intolerant to unknown extensions, but some servers may still be intolerant to specific extension ids. For example, RSA's BSAFE library used the extension id 40 for an experimental extension called "extended_random", associated with a theorized NSA backdoor. Extension id 40 happens to be the extension id used for TLS 1.3 key shares. David Benjamin reported that this library is still in use by some printers, which causes them to be TLS 1.3 intolerant. Matthew Green has a detailed write-up of this compatibility issue.
Help us understand the issue
Cloudflare has been working with the Mozilla Firefox team to help measure this phenomenon, and Google and Facebook have been doing their own measurements. These experiments are hard to perform because the developers need to get protocol variants into browsers, which can take the entire release cycle of the browser (often months) to get into the hands of the users seeing issues. Cloudflare now supports the latest (hopefully) middlebox-compatible TLS 1.3 draft version (draft 22), but there’s always a chance we find a middlebox that is incompatible with this version.
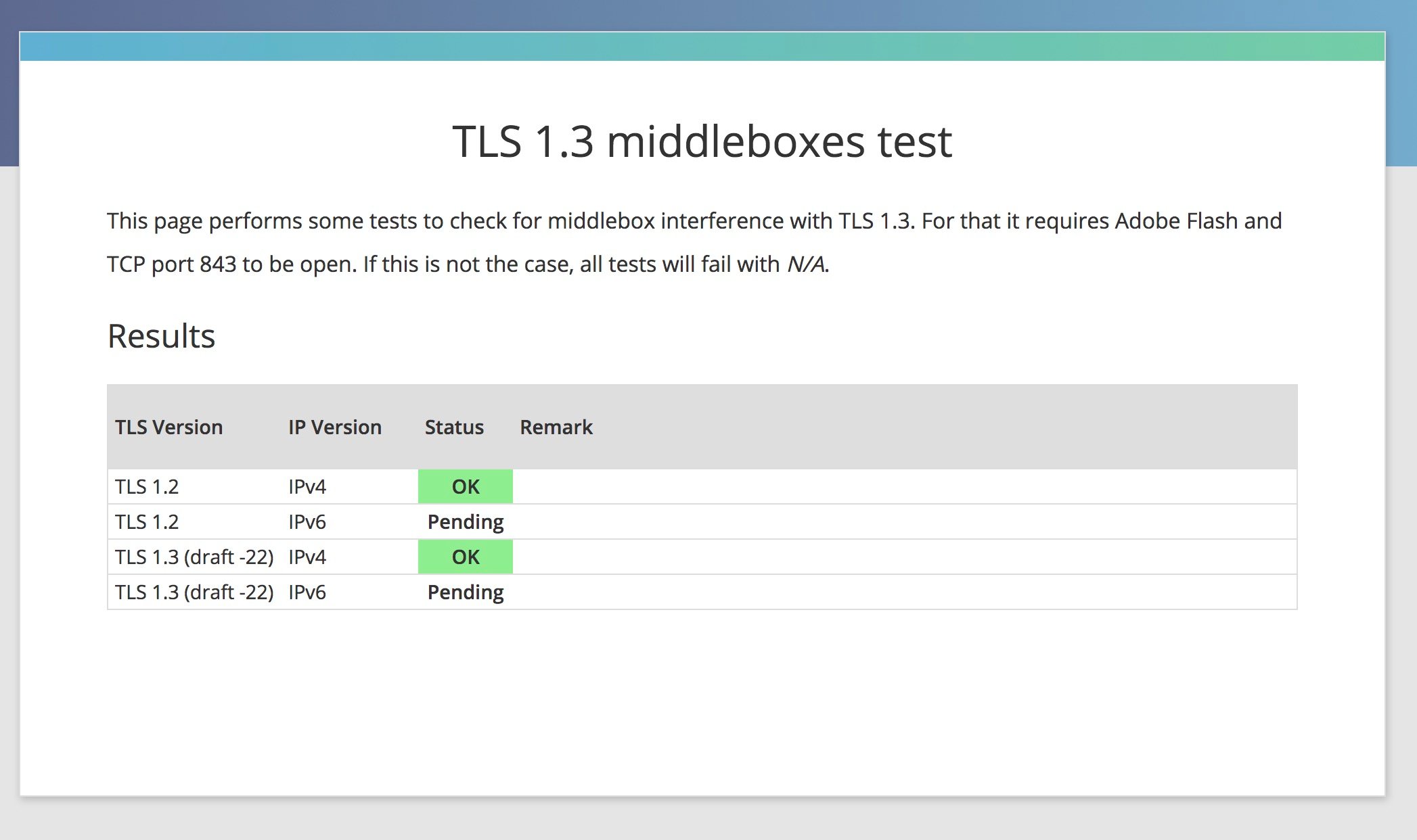
To sidestep the browser release cycle, we took a shortcut. We built a website that you can use to see if TLS 1.3 works from your browser’s vantage point. This test was built by our Crypto intern, Peter Wu. It uses Adobe Flash, because that’s the only widespread cross-platform way to get access to raw sockets from a browser.
How it works:
- We cross-compiled our Golang-based TLS 1.3 client library (tls-tris) to JavaScript
- We build a JavaScript library (called jssock) that implements tls-tris on the low-level socket interface network exposed through Adobe Flash
- We connect to a remote server using TLS 1.2 and TLS 1.3 and compare the results
If there is a mismatch, we gather information from the connection on both sides and send it back for analysis
If you see a failure, let us know! If you’re in a corporate environment, share the middlebox information, if you’re on a residential network, tell us who your ISP is.
![Why TLS 1.3 isn't in browsers yet]()
We’re excited for TLS 1.3 to finally be enabled by default in browsers. This experiment will hopefully help prove that the latest changes make it safe for users to upgrade.